Corpse Party 2021 (PATCH ITA - UPDATE)
ENG VERSION
Everything is progressing well, unfortunately it takes time because:
- Every dialogue line needs to be checked one by one.
- Some dialogue lines need to be re-adjusted to fit inside the Text Box.
- Tools need to be fixed.
As I adjust the tools, one part has been particularly challenging: separating some parts, as they would easily break during the translation application.
def should_be_separate_line(line: str) -> bool:
patterns = [
r'^[^:]{1,80}:', # Dialogue lines
r'^\*[^*]+\*', # Sound effects
r'^\[.*\]$', # Text in square brackets
r'^(\d{1,2}\s*/\s*\d{1,2})', # Dates
r'^".*"$', # Text in quotes
r'^\.{3}', # Lines starting with ...
]
return any(re.match(pattern, line) for pattern in patterns)
Also, inside the translation JSON files there are a lot of Japanese characters (used for debugging or cut content), so that’s another check to do:
CJK_RE = re.compile(r'[\u3000-\u303F\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]')
passthrough = bool(CJK_RE.search(s) or re.search(r'\btest\b', s, flags=re.I))
is_passthrough_block = any(CJK_RE.search(line) or re.search(r'\btest\b', line, flags=re.I) for line in b['orig'])
On the translation side, the first revisions are starting. Unfortunately, some dialogue lines are too long, so we are trying to find a way to re-adjust them properly.
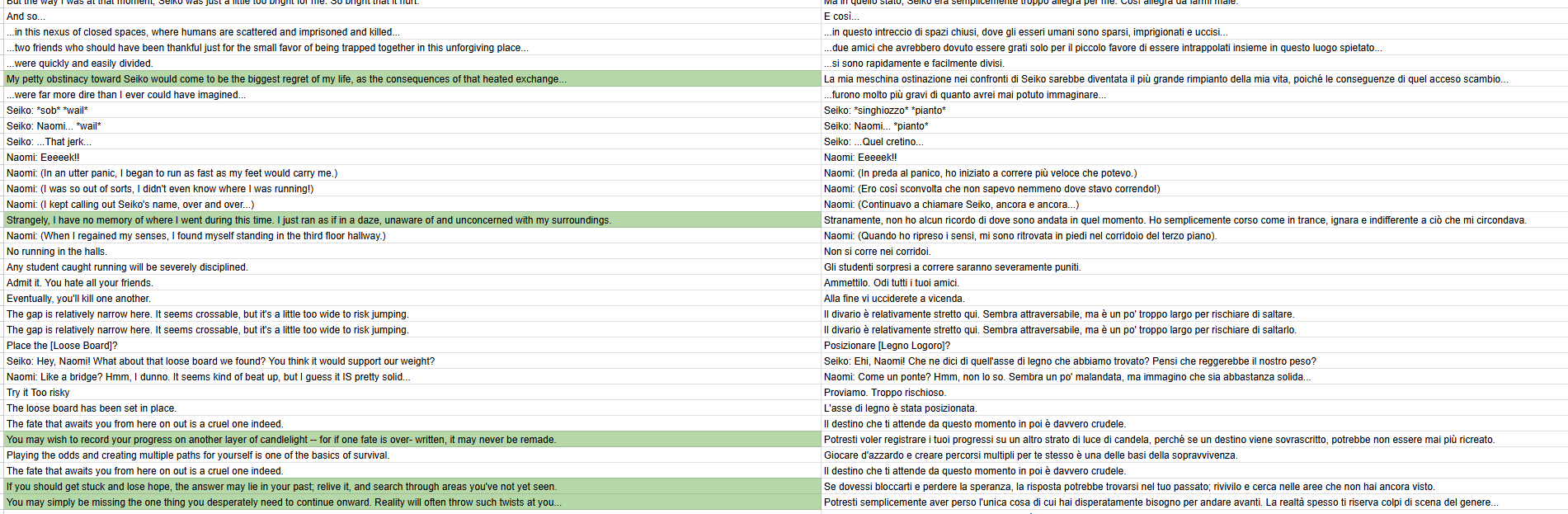
For example, I don’t know what happened here, lol. Of course, this silly error will be fixed, lol.

For now, we keep moving forward. I don’t have an exact date for the next beta(2). In the meantime, you can try the beta(1) and give us feedback.
~Foxy
ITA VERSION:
Sta procedendo bene, purtroppo ci vuole tempo, perché:
- Bisogna ricontrollare tutti i dialoghi uno a uno.
- Ri-adattare alcune linee di dialogo per farle stare nel Text Box.
- Sistemare i tools.
Man mano che aggiusto i tools, una parte mi ha messo a dura prova: separare alcune parti, perché si rompevano facilmente durante l’applicazione della traduzione.
def should_be_separate_line(line: str) -> bool:
patterns = [
r'^[^:]{1,80}:', # Linee di dialogo
r'^\*[^*]+\*', # Effetti sonori
r'^\[.*\]$', # Testo tra parentesi quadre
r'^(\d{1,2}\s*/\s*\d{1,2})', # Date
r'^".*"$', # Testo tra virgolette
r'^\.{3}', # Linee che iniziano con ...
]
return any(re.match(pattern, line) for pattern in patterns)
In più, all’interno dei JSON della traduzione ci sono molti caratteri giapponesi (usati per debug oppure contenuti tagliati), quindi c’è un altro check da fare F per me:
CJK_RE = re.compile(r'[\u3000-\u303F\u3040-\u309F\u30A0-\u30FF\u4E00-\u9FFF]')
passthrough = bool(CJK_RE.search(s) or re.search(r'\btest\b', s, flags=re.I))
is_passthrough_block = any(CJK_RE.search(line) or re.search(r'\btest\b', line, flags=re.I) for line in b['orig'])
Lato traduzione, si iniziano a fare le prime revisioni. Purtroppo alcune linee di dialogo sono troppo lunghe, quindi si cerca di trovare un modo per ri-adattarle correttamente.
Per esempio qui non so cosa sia successo, lol. Ovviamente si sistemerà questo errore stupido, lol.
Per il momento si procede, non ho una data precisa per la prossima beta(2). Nel frattempo potete provare la beta(1) e darci un feedback.
~Foxy